- Welcome to AHXproject.
AHXproject
< | >
Recent posts
#1
Ubuntu Blog / Ubuntu’s virtualization hardw...
Last post by tim - Jul 29, 2026, 04:41 AMUbuntu's virtualization hardware enablement (HWE) stack: a new model for confidential computing enablement
Confidential computing is moving quickly.
The foundation is already here: AMD SEV-SNP and Intel TDX have made it possible to run confidential virtual machines (VMs) with stronger protection for data in use. Ubuntu 26.04 Long Term Support (LTS ) brings integrated host and guest support for both of these technologies, making confidential computing a native part of the Ubuntu virtualization offering..
However, The next wave of features is still being developed and upstreamed. Live migration for confidential VMs, trusted device assignment, accelerator support, improved attestation flows, and technologies such as the TEE Device Interface Security Protocol (TDISP) will all require changes across the virtualization stack. These features do not depend on one component alone; they need support across the kernel, KVM, QEMU, libvirt, OVMF, and the surrounding tooling before anyone can actually make use of them.
That creates a challenge for any enterprise Linux distribution: production environments want LTS stability, but hardware innovation does not wait two years. How do we solve it?
Enabling newer hardware on LTS releases
Ubuntu LTS releases are designed for production: they give organizations a stable base, a predictable lifecycle, and long-term security maintenance. Those features are exactly why enterprises use them for critical infrastructure.
However, virtualization is closely tied to hardware. When CPU vendors add new capabilities, the software stack has to evolve with them. For confidential computing, that stack includes the kernel and KVM, QEMU, libvirt, firmware such as OVMF, and management tooling.
This is important, because confidential computing features rarely arrive on all of the relevant components at once. For instance, a processor may support a capability before the kernel has all the interfaces needed to expose it: QEMU may need new support to model the feature, libvirt may need new abstractions so users can configure it without writing complex QEMU command lines, OVMF may need changes so confidential guests can boot correctly, and attestation components may need to mature so workloads can prove where, and how, they are running. Only when these pieces line up does the feature actually become usable.
Before Ubuntu 26.04 LTS, Ubuntu already had a Hardware Enablement model for the kernel. This is a core part of confidential computing enablement: it includes KVM support, memory-management changes, CPU feature enablement, and the low-level interfaces that confidential virtual machines depend on.
But the kernel is only one layer. If the kernel moves forwards while QEMU, libvirt or firmware remain too far behind, users can still be blocked from using new virtualization capabilities end to end. Confidential computing makes this especially visible because the feature boundary crosses several layers at once.
That is why a traditional LTS model can be difficult for fast-moving virtualization features. If users have to wait for the next LTS to get newer virtualization components, they may be forced to choose between platform stability and access to new hardware capabilities.
For confidential computing, that trade-off is not ideal. The technology is becoming more relevant to regulated workloads, AI infrastructure, sovereign clouds, financial services, and sensitive data processing. The users in these scenarios need stability, but they also need access to the features that make new hardware useful.
Introducing the virtualization HWE stack
Ubuntu 26.04 LTS introduces a HWE stack for virtualization.
The idea is simple: stay on Ubuntu LTS, but have the option to use newer virtualization components as they become available and validated.
The virtualization HWE stack includes:
This extends HWE beyond the kernel. Instead of only enabling newer hardware through the kernel, Ubuntu can now also move the key virtualization components that are needed to expose, configure and operate that hardware in virtualized environments.
The model works as a rolling enablement window inside the LTS lifecycle. During the first two years of the Ubuntu LTS, the virtualization HWE stack is upgraded every six months to match the latest upstream versions supported in Ubuntu. In practice, that means the stack can follow the cadence of Ubuntu interim releases, while still giving users an LTS base.
The timing is deliberate, as new versions are not pushed into the LTS immediately. They are introduced after they have already been exercised in interim Ubuntu releases, giving time for validation before they reach LTS users.
This gives users a better balance: the operational confidence of an LTS release, with a path to newer virtualization capabilities when they need them.
What is the rolling model?
The rolling model is important because hardware enablement is not a one-time event. A new confidential computing feature may land upstream in stages. First, kernel support may appear. Then QEMU support follows. Then libvirt adds a way to configure it properly. Firmware support may mature later. Tooling and documentation may come after that. For users, the feature only becomes useful when enough of that chain is present in the distribution.
A six-month HWE cadence gives Ubuntu a way to pick up that work regularly, without turning the LTS into an uncontrolled rolling release. This is the key balance: the base OS remains an LTS, but the virtualization stack has a supported path to move forward during the period when hardware enablement is changing fastest.
For confidential computing, that is essential. Features such as confidential VM live migration, trusted I/O, trusted device assignment, and accelerator enablement will mature over several upstream cycles. A rolling HWE model gives Ubuntu a mechanism to bring those capabilities to LTS users as the stack matures, rather than making them wait for the next LTS release.
Opt-in by design
The virtualization HWE stack is opt-in: existing systems continue to use the base virtualization stack, unless the user explicitly chooses the HWE stack. For organizations that prioritize minimal change, the base stack remains the default. For users who need newer hardware enablement, the HWE stack provides a supported path.
Ubuntu also provides the ubuntu_virt_helper tool to help users manage the stack as a unit. That is important, because virtualization is not one package; it is a set of components that need to move together. Switching only one component can leave a system in an incomplete or inconsistent state.
What does the HWE stack mean for Ubuntu users?
For users building confidential computing environments, the virtualization HWE stack means they do not need to choose between two bad options: they do not need to leave LTS just to access newer virtualization capabilities. They also do not need to wait for the next LTS before they can benefit from features that are already moving through the upstream stack.
Instead, they can stay on Ubuntu 26.04 LTS and opt into a newer virtualization stack when their hardware, workload or feature requirements demand it.
This is especially relevant for organizations working on:
For these users, the operating system is not just a place where workloads run. It is the layer that turns hardware capabilities into something usable, maintainable and supportable.
Why Ubuntu can stay ahead
Confidential computing will continue to evolve over the next several years.
The industry still has work to do around live migration, trusted I/O, accelerator enablement, attestation, orchestration, and operational tooling. These features will not become real for users the moment they appear in a processor specification. They become real when the full software stack supports them.
The virtualization HWE model gives Ubuntu a structured way to bring new virtualization capabilities into the LTS lifecycle, without forcing users onto interim releases. It also gives Canonical a way to support the pace of confidential computing development while preserving the qualities that make Ubuntu LTS useful in production.
With Ubuntu 26.04 LTS and the new virtualization HWE stack, Ubuntu is better positioned to remain a leading platform for confidential computing as the technology continues to mature.
Learn more
Confidential computing
How Ubuntu enables verifiable private AI with confidential computing on bare metal
Sovereign clouds: enhance data security with confidential computing
Confidential computing is moving quickly. The foundation is already here: AMD SEV-SNP and Intel TDX have made it possible to run confidential virtual machines (VMs) with stronger protection for data in use. Ubuntu 26.04 Long Term Support (LTS) brings integrated host and guest support for both of these technologies, making confidential computing a native part [...]
Source: https://ubuntu.com//blog/ubuntu-virtualization-hwe-stack-confidential-computing Jul 27, 2026, 01:57 PM
Confidential computing is moving quickly.
The foundation is already here: AMD SEV-SNP and Intel TDX have made it possible to run confidential virtual machines (VMs) with stronger protection for data in use. Ubuntu 26.04 Long Term Support (LTS ) brings integrated host and guest support for both of these technologies, making confidential computing a native part of the Ubuntu virtualization offering..
However, The next wave of features is still being developed and upstreamed. Live migration for confidential VMs, trusted device assignment, accelerator support, improved attestation flows, and technologies such as the TEE Device Interface Security Protocol (TDISP) will all require changes across the virtualization stack. These features do not depend on one component alone; they need support across the kernel, KVM, QEMU, libvirt, OVMF, and the surrounding tooling before anyone can actually make use of them.
That creates a challenge for any enterprise Linux distribution: production environments want LTS stability, but hardware innovation does not wait two years. How do we solve it?
Enabling newer hardware on LTS releases
Ubuntu LTS releases are designed for production: they give organizations a stable base, a predictable lifecycle, and long-term security maintenance. Those features are exactly why enterprises use them for critical infrastructure.
However, virtualization is closely tied to hardware. When CPU vendors add new capabilities, the software stack has to evolve with them. For confidential computing, that stack includes the kernel and KVM, QEMU, libvirt, firmware such as OVMF, and management tooling.
This is important, because confidential computing features rarely arrive on all of the relevant components at once. For instance, a processor may support a capability before the kernel has all the interfaces needed to expose it: QEMU may need new support to model the feature, libvirt may need new abstractions so users can configure it without writing complex QEMU command lines, OVMF may need changes so confidential guests can boot correctly, and attestation components may need to mature so workloads can prove where, and how, they are running. Only when these pieces line up does the feature actually become usable.
Before Ubuntu 26.04 LTS, Ubuntu already had a Hardware Enablement model for the kernel. This is a core part of confidential computing enablement: it includes KVM support, memory-management changes, CPU feature enablement, and the low-level interfaces that confidential virtual machines depend on.
But the kernel is only one layer. If the kernel moves forwards while QEMU, libvirt or firmware remain too far behind, users can still be blocked from using new virtualization capabilities end to end. Confidential computing makes this especially visible because the feature boundary crosses several layers at once.
That is why a traditional LTS model can be difficult for fast-moving virtualization features. If users have to wait for the next LTS to get newer virtualization components, they may be forced to choose between platform stability and access to new hardware capabilities.
For confidential computing, that trade-off is not ideal. The technology is becoming more relevant to regulated workloads, AI infrastructure, sovereign clouds, financial services, and sensitive data processing. The users in these scenarios need stability, but they also need access to the features that make new hardware useful.
Introducing the virtualization HWE stack
Ubuntu 26.04 LTS introduces a HWE stack for virtualization.
The idea is simple: stay on Ubuntu LTS, but have the option to use newer virtualization components as they become available and validated.
The virtualization HWE stack includes:
- qemu-hwe, for hypervisor and system emulation
- libvirt-hwe, for virtualization management
- edk2-hwe, including OVMF firmware, for UEFI support
- seabios-hwe, for BIOS firmware compatibility
This extends HWE beyond the kernel. Instead of only enabling newer hardware through the kernel, Ubuntu can now also move the key virtualization components that are needed to expose, configure and operate that hardware in virtualized environments.
The model works as a rolling enablement window inside the LTS lifecycle. During the first two years of the Ubuntu LTS, the virtualization HWE stack is upgraded every six months to match the latest upstream versions supported in Ubuntu. In practice, that means the stack can follow the cadence of Ubuntu interim releases, while still giving users an LTS base.
The timing is deliberate, as new versions are not pushed into the LTS immediately. They are introduced after they have already been exercised in interim Ubuntu releases, giving time for validation before they reach LTS users.
This gives users a better balance: the operational confidence of an LTS release, with a path to newer virtualization capabilities when they need them.
What is the rolling model?
The rolling model is important because hardware enablement is not a one-time event. A new confidential computing feature may land upstream in stages. First, kernel support may appear. Then QEMU support follows. Then libvirt adds a way to configure it properly. Firmware support may mature later. Tooling and documentation may come after that. For users, the feature only becomes useful when enough of that chain is present in the distribution.
A six-month HWE cadence gives Ubuntu a way to pick up that work regularly, without turning the LTS into an uncontrolled rolling release. This is the key balance: the base OS remains an LTS, but the virtualization stack has a supported path to move forward during the period when hardware enablement is changing fastest.
For confidential computing, that is essential. Features such as confidential VM live migration, trusted I/O, trusted device assignment, and accelerator enablement will mature over several upstream cycles. A rolling HWE model gives Ubuntu a mechanism to bring those capabilities to LTS users as the stack matures, rather than making them wait for the next LTS release.
Opt-in by design
The virtualization HWE stack is opt-in: existing systems continue to use the base virtualization stack, unless the user explicitly chooses the HWE stack. For organizations that prioritize minimal change, the base stack remains the default. For users who need newer hardware enablement, the HWE stack provides a supported path.
Ubuntu also provides the ubuntu_virt_helper tool to help users manage the stack as a unit. That is important, because virtualization is not one package; it is a set of components that need to move together. Switching only one component can leave a system in an incomplete or inconsistent state.
What does the HWE stack mean for Ubuntu users?
For users building confidential computing environments, the virtualization HWE stack means they do not need to choose between two bad options: they do not need to leave LTS just to access newer virtualization capabilities. They also do not need to wait for the next LTS before they can benefit from features that are already moving through the upstream stack.
Instead, they can stay on Ubuntu 26.04 LTS and opt into a newer virtualization stack when their hardware, workload or feature requirements demand it.
This is especially relevant for organizations working on:
- Confidential VMs with AMD SEV-SNP or Intel TDX
- Regulated workloads that require stronger isolation
- AI workloads that need confidential inference or accelerator support
- Private cloud and sovereign cloud platforms
- Infrastructure that needs long-term maintenance, without falling behind hardware capabilities
For these users, the operating system is not just a place where workloads run. It is the layer that turns hardware capabilities into something usable, maintainable and supportable.
Why Ubuntu can stay ahead
Confidential computing will continue to evolve over the next several years.
The industry still has work to do around live migration, trusted I/O, accelerator enablement, attestation, orchestration, and operational tooling. These features will not become real for users the moment they appear in a processor specification. They become real when the full software stack supports them.
The virtualization HWE model gives Ubuntu a structured way to bring new virtualization capabilities into the LTS lifecycle, without forcing users onto interim releases. It also gives Canonical a way to support the pace of confidential computing development while preserving the qualities that make Ubuntu LTS useful in production.
With Ubuntu 26.04 LTS and the new virtualization HWE stack, Ubuntu is better positioned to remain a leading platform for confidential computing as the technology continues to mature.
Learn more
Confidential computing
How Ubuntu enables verifiable private AI with confidential computing on bare metal
Sovereign clouds: enhance data security with confidential computing
Confidential computing is moving quickly. The foundation is already here: AMD SEV-SNP and Intel TDX have made it possible to run confidential virtual machines (VMs) with stronger protection for data in use. Ubuntu 26.04 Long Term Support (LTS) brings integrated host and guest support for both of these technologies, making confidential computing a native part [...]
Source: https://ubuntu.com//blog/ubuntu-virtualization-hwe-stack-confidential-computing Jul 27, 2026, 01:57 PM
#2
Ubuntu Blog / Confidential computing and th...
Last post by tim - Jul 29, 2026, 04:41 AMConfidential computing and the new regulatory focus on data in use
Most organizations already understand encryption at rest and encryption in transit. These controls are mature, widely deployed, and often explicitly referenced in security frameworks.
However, runtime is different: when an application processes sensitive information, that data is typically available in memory. In a traditional infrastructure model, the workload owner may need to trust a large stack of privileged components below the workload, such as the firmware, the hypervisor, the host operating system, and the infrastructure operator. For many workloads, that trust model is acceptable; however, for highly regulated workloads, it can become a problem.
This issue can be seen in highly sensitive use cases, such as financial analytics, healthcare research, public sector data sharing, fraud detection, confidential AI inference, or cross-organization collaboration: In each case, the organization wants to use sensitive data, but it also needs to reduce who or what can access it during processing.
Confidential computing is a hardware-backed approach to protecting data while it is being processed. It uses trusted execution environments to help isolate workloads from parts of the underlying infrastructure, reducing the amount of software and privileged access that must be trusted by default.
That is whereconfidential computing comes in. It does not replace encryption at rest, network encryption, access control, or vulnerability management. It complements them by extending protection into runtime.
Regulations are catching up to this shift in data protection needs. And while regulators may not always use the words "confidential computing" in order to remain technology-neutral, they are increasingly asking organizations to demonstrate outcomes that confidential computing was designed to support: confidentiality, reduced third-party risk, stronger data governance, secure AI systems, and better control over sensitive workloads across cloud, edge, on-prem, and hybrid environments.
In other words, confidential computing is moving from an infrastructure feature to a compliance-relevant security architecture. In the rest of this blog post, we will explore this development.
Data in use is becoming a recognized control area
One of the clearest signs of this change is that data in use is starting to appear as its own control area.
NIST Cybersecurity Framework 2.0 makes this explicit. Its data security category includes protections for data at rest, data in transit, and data in use. The subcategoryPR.DS-10 states that the confidentiality, integrity, and availability of data in use should be protected.
This is important because it completes the familiar data protection model. Security teams have long been asked how they protect stored data and data moving across networks. They are now being asked the same question about data during processing.
The same pattern appears in US federal zero trust guidance. TheFederal Zero Trust Data Security Guide , published by the CISO Council and CDO Council, includes computational isolation and confidential computing as part of the data security discussion. That is a useful signal: confidential computing is being discussed not only as a cloud feature, but as part of a broader data-centric security model.
Financial regulators are moving in a similar direction. In the UK, the Prudential Regulation Authority'sSS2/21 on outsourcing and third-party risk management expects regulated firms to implement robust controls for data in transit, data in memory, and data at rest. For financial institutions using external technology providers, runtime protection is becoming part of the outsourcing and third-party risk conversation.
This does not mean every framework now mandates confidential computing; Most still remain technology-neutral. But the direction is clear: protecting data in use is becoming a recognized security outcome, and confidential computing is one of the most direct ways to support it.
Standards are catching up with the architecture
A useful signal that confidential computing is maturing is that it is now being formalized in standards and public guidance.
ISO/IEC is developing a dedicated confidential computing standard,ISO/IEC DIS 25093-1 , under the title "Cybersecurity , Confidential computing, Part 1: Overview and concepts". That is a significant development because it shows the term is moving beyond vendor-specific implementation and into international standardization.
NIST has also published guidance on hardware-enabled security and confidential computing. Its draft report,Hardware-Enabled Security: Confidential Computing of Data in Use in Cloud Computing and AI Workloads , frames confidential computing as a way to protect data while it is being processed in memory and active use, with particular relevance for cloud and AI workloads.
This is important for regulated organizations because standards often become the bridge between broad legal requirements and practical technical controls. A law may require "appropriate security" – and a standard can help define what that looks like in practice.
This is also happening outside of Europe and the US. China has also publishedGB/T 45230-2025 , a national standard titled "Data security technology , General framework for the confidential computing", released in January 2025 and implemented from August 2025. It is another sign that confidential computing is becoming a formal security category rather than only a vendor term.
Regulation is converging on the same problem
The clearest example is theGDPR . GDPR does not mandate confidential computing by name. But Article 32 requires appropriate technical and organizational measures, including encryption and the ability to ensure ongoing confidentiality, integrity, availability, and resilience of processing systems and services. "Processing" is the important part here.
If an organization processes sensitive personal data, then the security question cannot stop at storage and transmission. The organization also has to ask what happens while that data is actively being used. Who can access the workload? What can the host see? What is included in the trusted computing base? Can the workload prove that it is running in a protected environment before secrets are released?
Confidential computing gives security teams a concrete way to answer those questions.
The same pattern appears in the financial sector.DORA , the EU Digital Operational Resilience Act, has applied since January 2025, and it focuses on ICT risk, operational resilience and third-party technology dependencies. The act does not simply say "deploy confidential computing", but it creates a regulatory environment where financial institutions need stronger evidence that sensitive workloads remain protected across outsourced ICT environments.
The UK PRA'sSS2/21 makes the data-in-use point even more explicit by referring to robust controls for data in memory, alongside data in transit and data at rest. For sensitive financial workloads, confidential computing can become part of the control set used to reduce runtime exposure and strengthen assurance.
NIS2 follows a similar logic as it requires essential and important entities to apply appropriate and proportionate cybersecurity risk-management measures. These organizations include sectors such as energy, transport, banking, health, digital infrastructure, and public administration. Many of them are modernizing through cloud, edge, and data-driven systems. Many of them are also processing data that is operationally or socially sensitive.
For those sectors, runtime protection is not a niche concern. It is part of the broader question of cyber resilience.
Sovereignty is making runtime trust visible
Confidential computing is also becoming central to sovereign technology discussions. Sovereignty is often reduced to geography: where data is stored, where infrastructure is operated, and which jurisdiction applies. Those questions are important, but they are not the full story.
A more complete sovereignty model also asks: who can technically access the workload? Can administrators inspect data while it is being processed? Can the infrastructure provider access memory? Can the tenant verify the state of the environment before releasing keys or secrets?
This is where confidential computing becomes a sovereignty control rather than simply a privacy feature.
The French cybersecurity agencyANSSI has described confidential computing in itstechnical position paper as a set of technologies for executing sensitive workloads in remote environments, complementing encryption at rest and in transit by encrypting data in use and shielding it from direct inspection by administrators on shared infrastructure.
This framing acknowledges both the promise and the limitations of the technology. Confidential computing is not magic: it does not remove the need for secure software, patched systems, measured boot, key management, monitoring, or carefully designed architecture. What it does do is reduce the amount of infrastructure that has to be trusted by default.
For sovereign systems, that reduction is powerful. It enables a more nuanced model: not "trust the provider completely", and not "never run sensitive workloads on shared infrastructure", but instead "use infrastructure with stronger technical boundaries, attestation, and cryptographic control".
Healthcare shows why data in use is important
Healthcare is one of the clearest examples of why confidential computing is becoming relevant to regulation.
Health data is highly sensitive, but it is also increasingly valuable for research, public health, personalized medicine, and AI. The challenge is that healthcare systems need to make data useful without making it unnecessarily exposed.
TheEuropean Health Data Space is a good example of this change. It aims to create a framework for the use and reuse of electronic health data across the EU, including secondary use for research, innovation, policy-making, and public health. That kind of model depends on trust: patients, providers, researchers, and regulators all need confidence that sensitive data can be analyzed under strict safeguards.
Traditional encryption helps protect health data when it is stored or transmitted. But research, analytics and AI workloads require data to be processed. That is the point where confidential computing becomes especially relevant.
By protecting workloads and data during computation, confidential computing can help healthcare organizations build stronger technical boundaries around sensitive analysis environments. It can reduce exposure to infrastructure operators, support attestation before data or keys are released, and make it easier to design systems where data can be used without broadening the circle of trust.
This does not make healthcare data sharing simple. Governance, consent, access controls, auditability, anonymization, pseudonymization, and legal safeguards are still mandatory . But confidential computing gives healthcare organizations a practical way to strengthen the processing environment itself.
For healthcare, the regulatory question is no longer only "where is the data stored?" It is also "how is the data protected while it is being used?"
Secure data sharing needs secure processing
Another area where confidential computing fits naturally is data sharing.
TheEU Data Governance Act introduces the concept of secure processing environments: physical or virtual environments, combined with organizational measures, that allow data to be used while maintaining legal requirements around confidentiality, integrity, access, and supervision. This is the exact kind of problem confidential computing was built to help solve.
Many organizations want to collaborate on sensitive data without exposing raw datasets more broadly than necessary. Healthcare researchers want to analyze patient data. Public sector bodies want to reuse data for policy and planning. Financial institutions want to collaborate on fraud detection. Companies want to run analytics across commercial datasets without revealing more than the computation requires.
In these cases, the question is not only "is the database encrypted?" The question is "can the processing environment itself be trusted?"
Confidential computing can help create stronger technical boundaries for these environments. It can support attestation before data access, reduce exposure to infrastructure administrators and help organizations design systems where sensitive data can be used with fewer parties in the trusted computing base.
That makes it highly relevant to data spaces, data clean rooms, and regulated analytics.
AI raises the stakes for data in use
AI makes the regulatory relevance of confidential computing even clearer.
AI workloads often process highly sensitive inputs: prompts, embeddings, documents, training data, fine-tuning datasets, model weights, and inference outputs. In some cases, the model itself may be valuable intellectual property. In others, the data being processed may be personal, confidential, classified, or commercially sensitive.
TheEU AI Act requires high-risk AI systems to achieve appropriate levels of accuracy, robustness and cybersecurity throughout their lifecycle. That lifecycle framing is important. Security is not a one-time property of the model. It depends on how the model is deployed, what data it processes, how it is updated, how it is monitored, and how its surrounding infrastructure is protected.
Confidential computing can help secure parts of that lifecycle, especially where organizations want to run AI workloads on shared, remote, or hybrid infrastructure without exposing sensitive data or models to the underlying platform.
This is why confidential AI is becoming such an important use case. It is not only about privacy. It is also about protecting intellectual property, reducing third-party risk, supporting regulated inference, and enabling organizations to adopt AI without giving up control over sensitive assets.
The same idea is starting to appear in AI policy discussions beyond traditional compliance. For example, public comments related to the USAmerican AI Exports Program have recommended accelerator-level confidential computing as one way to protect AI model weights and systems in export packages. That is not the same as a regulatory mandate, but it shows how confidential computing is entering wider discussions about AI security, trust, and geopolitical risk.
Other frameworks point in the same direction
Not every relevant framework is built around privacy, financial resilience, or AI. Some are sector-specific or industry-led, but they point to the same underlying issue.
ThePayment Card Industry Data Security Standard is designed to protect payment account data through technical and operational requirements.PCI DSS v4.0.1 is not a confidential computing regulation, but payment environments often involve sensitive data moving through memory, applications, and processing systems. For high-risk payment workloads, runtime protection can become part of a broader defence-in-depth strategy.
TheCloud Security Alliance has also highlighted the need for cloud-native security architectures and guidance for protecting sensitive workloads in modern cloud environments. Its work is not regulation, but it often shapes how cloud providers and customers think about practical controls.
Singapore'sMonetary Authority of Singapore provides technology risk management guidance for financial institutions. Like DORA and PRA SS2/21, it reflects a wider financial-sector expectation: organizations need strong governance and technical controls for technology risk, especially where critical or sensitive workloads depend on third-party infrastructure.
The pattern is consistent. Whether the language is data in use, data in memory, secure processing, operational resilience, cybersecurity, or zero trust, the direction is the same: sensitive data needs protection during computation, not only before and after it.
A new baseline for sensitive workloads
The end result of all this is clear to see: regulation is becoming more concerned with how data is processed, instead of solely focusing on where and how it is stored. Financial risk management is becoming more focused on third-party technology dependencies. AI regulation is making lifecycle security more important. Healthcare and data-sharing initiatives are making secure processing environments more important. Sovereignty discussions are moving beyond location and into technical control.
All of these trends point toward the same conclusion: data in use is becoming a regulatory concern.
Confidential computing will not be mandatory for every workload. It will not replace existing security controls. It will not eliminate the need to trust hardware vendors, firmware, guest software or the application itself.
But for sensitive and regulated workloads, it gives organizations a way to shrink the trust boundary, strengthen runtime protection and provide stronger evidence that systems are being designed with confidentiality in mind.
That is why confidential computing is becoming part of the compliance conversation. Encryption at rest and in transit gave us the first two pillars of data protection. Confidential computing adds the third: protection while data is in use.
For organizations building the next generation of regulated cloud, edge, AI, and data-sharing systems, that third pillar is becoming much harder to treat as optional.
The role of Canonical and Ubuntu
Confidential computing is often described as a hardware capability. That is true, but it is only part of the story. Regulated organizations do not deploy processors in isolation. They deploy platforms. They need kernels, hypervisors, images, firmware, tooling, security updates, and long-term maintenance that work together.
That is why the operating system is important for confidential computing. With Ubuntu 26.04 LTS, Canonical brings integrated host and guest support for both AMD SEV-SNP and Intel TDX. These are two of the main technologies used to protect confidential virtual machines, and supporting both sides of the stack is what makes confidential computing practical for real deployments.
For regulated organizations, this is what turns confidential computing from a hardware feature into something they can confidently deploy at scale. If you're interested in discussing your confidential computing needs in more detail, don't hesitate to contact us .
Most organizations already understand encryption at rest and encryption in transit. These controls are mature, widely deployed, and often explicitly referenced in security frameworks. However, runtime is different: when an application processes sensitive information, that data is typically available in memory. In a traditional infrastructure model, the workload owner may need to trust a large [...]
Source: https://ubuntu.com//blog/confidential-computing-and-the-new-regulatory-focus-on-data-in-use Jul 24, 2026, 06:27 PM
Most organizations already understand encryption at rest and encryption in transit. These controls are mature, widely deployed, and often explicitly referenced in security frameworks.
However, runtime is different: when an application processes sensitive information, that data is typically available in memory. In a traditional infrastructure model, the workload owner may need to trust a large stack of privileged components below the workload, such as the firmware, the hypervisor, the host operating system, and the infrastructure operator. For many workloads, that trust model is acceptable; however, for highly regulated workloads, it can become a problem.
This issue can be seen in highly sensitive use cases, such as financial analytics, healthcare research, public sector data sharing, fraud detection, confidential AI inference, or cross-organization collaboration: In each case, the organization wants to use sensitive data, but it also needs to reduce who or what can access it during processing.
Confidential computing is a hardware-backed approach to protecting data while it is being processed. It uses trusted execution environments to help isolate workloads from parts of the underlying infrastructure, reducing the amount of software and privileged access that must be trusted by default.
That is whereconfidential computing comes in. It does not replace encryption at rest, network encryption, access control, or vulnerability management. It complements them by extending protection into runtime.
Regulations are catching up to this shift in data protection needs. And while regulators may not always use the words "confidential computing" in order to remain technology-neutral, they are increasingly asking organizations to demonstrate outcomes that confidential computing was designed to support: confidentiality, reduced third-party risk, stronger data governance, secure AI systems, and better control over sensitive workloads across cloud, edge, on-prem, and hybrid environments.
In other words, confidential computing is moving from an infrastructure feature to a compliance-relevant security architecture. In the rest of this blog post, we will explore this development.
Data in use is becoming a recognized control area
One of the clearest signs of this change is that data in use is starting to appear as its own control area.
NIST Cybersecurity Framework 2.0 makes this explicit. Its data security category includes protections for data at rest, data in transit, and data in use. The subcategoryPR.DS-10 states that the confidentiality, integrity, and availability of data in use should be protected.
This is important because it completes the familiar data protection model. Security teams have long been asked how they protect stored data and data moving across networks. They are now being asked the same question about data during processing.
The same pattern appears in US federal zero trust guidance. TheFederal Zero Trust Data Security Guide , published by the CISO Council and CDO Council, includes computational isolation and confidential computing as part of the data security discussion. That is a useful signal: confidential computing is being discussed not only as a cloud feature, but as part of a broader data-centric security model.
Financial regulators are moving in a similar direction. In the UK, the Prudential Regulation Authority'sSS2/21 on outsourcing and third-party risk management expects regulated firms to implement robust controls for data in transit, data in memory, and data at rest. For financial institutions using external technology providers, runtime protection is becoming part of the outsourcing and third-party risk conversation.
This does not mean every framework now mandates confidential computing; Most still remain technology-neutral. But the direction is clear: protecting data in use is becoming a recognized security outcome, and confidential computing is one of the most direct ways to support it.
Standards are catching up with the architecture
A useful signal that confidential computing is maturing is that it is now being formalized in standards and public guidance.
ISO/IEC is developing a dedicated confidential computing standard,ISO/IEC DIS 25093-1 , under the title "Cybersecurity , Confidential computing, Part 1: Overview and concepts". That is a significant development because it shows the term is moving beyond vendor-specific implementation and into international standardization.
NIST has also published guidance on hardware-enabled security and confidential computing. Its draft report,Hardware-Enabled Security: Confidential Computing of Data in Use in Cloud Computing and AI Workloads , frames confidential computing as a way to protect data while it is being processed in memory and active use, with particular relevance for cloud and AI workloads.
This is important for regulated organizations because standards often become the bridge between broad legal requirements and practical technical controls. A law may require "appropriate security" – and a standard can help define what that looks like in practice.
This is also happening outside of Europe and the US. China has also publishedGB/T 45230-2025 , a national standard titled "Data security technology , General framework for the confidential computing", released in January 2025 and implemented from August 2025. It is another sign that confidential computing is becoming a formal security category rather than only a vendor term.
Regulation is converging on the same problem
The clearest example is theGDPR . GDPR does not mandate confidential computing by name. But Article 32 requires appropriate technical and organizational measures, including encryption and the ability to ensure ongoing confidentiality, integrity, availability, and resilience of processing systems and services. "Processing" is the important part here.
If an organization processes sensitive personal data, then the security question cannot stop at storage and transmission. The organization also has to ask what happens while that data is actively being used. Who can access the workload? What can the host see? What is included in the trusted computing base? Can the workload prove that it is running in a protected environment before secrets are released?
Confidential computing gives security teams a concrete way to answer those questions.
The same pattern appears in the financial sector.DORA , the EU Digital Operational Resilience Act, has applied since January 2025, and it focuses on ICT risk, operational resilience and third-party technology dependencies. The act does not simply say "deploy confidential computing", but it creates a regulatory environment where financial institutions need stronger evidence that sensitive workloads remain protected across outsourced ICT environments.
The UK PRA'sSS2/21 makes the data-in-use point even more explicit by referring to robust controls for data in memory, alongside data in transit and data at rest. For sensitive financial workloads, confidential computing can become part of the control set used to reduce runtime exposure and strengthen assurance.
NIS2 follows a similar logic as it requires essential and important entities to apply appropriate and proportionate cybersecurity risk-management measures. These organizations include sectors such as energy, transport, banking, health, digital infrastructure, and public administration. Many of them are modernizing through cloud, edge, and data-driven systems. Many of them are also processing data that is operationally or socially sensitive.
For those sectors, runtime protection is not a niche concern. It is part of the broader question of cyber resilience.
Sovereignty is making runtime trust visible
Confidential computing is also becoming central to sovereign technology discussions. Sovereignty is often reduced to geography: where data is stored, where infrastructure is operated, and which jurisdiction applies. Those questions are important, but they are not the full story.
A more complete sovereignty model also asks: who can technically access the workload? Can administrators inspect data while it is being processed? Can the infrastructure provider access memory? Can the tenant verify the state of the environment before releasing keys or secrets?
This is where confidential computing becomes a sovereignty control rather than simply a privacy feature.
The French cybersecurity agencyANSSI has described confidential computing in itstechnical position paper as a set of technologies for executing sensitive workloads in remote environments, complementing encryption at rest and in transit by encrypting data in use and shielding it from direct inspection by administrators on shared infrastructure.
This framing acknowledges both the promise and the limitations of the technology. Confidential computing is not magic: it does not remove the need for secure software, patched systems, measured boot, key management, monitoring, or carefully designed architecture. What it does do is reduce the amount of infrastructure that has to be trusted by default.
For sovereign systems, that reduction is powerful. It enables a more nuanced model: not "trust the provider completely", and not "never run sensitive workloads on shared infrastructure", but instead "use infrastructure with stronger technical boundaries, attestation, and cryptographic control".
Healthcare shows why data in use is important
Healthcare is one of the clearest examples of why confidential computing is becoming relevant to regulation.
Health data is highly sensitive, but it is also increasingly valuable for research, public health, personalized medicine, and AI. The challenge is that healthcare systems need to make data useful without making it unnecessarily exposed.
TheEuropean Health Data Space is a good example of this change. It aims to create a framework for the use and reuse of electronic health data across the EU, including secondary use for research, innovation, policy-making, and public health. That kind of model depends on trust: patients, providers, researchers, and regulators all need confidence that sensitive data can be analyzed under strict safeguards.
Traditional encryption helps protect health data when it is stored or transmitted. But research, analytics and AI workloads require data to be processed. That is the point where confidential computing becomes especially relevant.
By protecting workloads and data during computation, confidential computing can help healthcare organizations build stronger technical boundaries around sensitive analysis environments. It can reduce exposure to infrastructure operators, support attestation before data or keys are released, and make it easier to design systems where data can be used without broadening the circle of trust.
This does not make healthcare data sharing simple. Governance, consent, access controls, auditability, anonymization, pseudonymization, and legal safeguards are still mandatory . But confidential computing gives healthcare organizations a practical way to strengthen the processing environment itself.
For healthcare, the regulatory question is no longer only "where is the data stored?" It is also "how is the data protected while it is being used?"
Secure data sharing needs secure processing
Another area where confidential computing fits naturally is data sharing.
TheEU Data Governance Act introduces the concept of secure processing environments: physical or virtual environments, combined with organizational measures, that allow data to be used while maintaining legal requirements around confidentiality, integrity, access, and supervision. This is the exact kind of problem confidential computing was built to help solve.
Many organizations want to collaborate on sensitive data without exposing raw datasets more broadly than necessary. Healthcare researchers want to analyze patient data. Public sector bodies want to reuse data for policy and planning. Financial institutions want to collaborate on fraud detection. Companies want to run analytics across commercial datasets without revealing more than the computation requires.
In these cases, the question is not only "is the database encrypted?" The question is "can the processing environment itself be trusted?"
Confidential computing can help create stronger technical boundaries for these environments. It can support attestation before data access, reduce exposure to infrastructure administrators and help organizations design systems where sensitive data can be used with fewer parties in the trusted computing base.
That makes it highly relevant to data spaces, data clean rooms, and regulated analytics.
AI raises the stakes for data in use
AI makes the regulatory relevance of confidential computing even clearer.
AI workloads often process highly sensitive inputs: prompts, embeddings, documents, training data, fine-tuning datasets, model weights, and inference outputs. In some cases, the model itself may be valuable intellectual property. In others, the data being processed may be personal, confidential, classified, or commercially sensitive.
TheEU AI Act requires high-risk AI systems to achieve appropriate levels of accuracy, robustness and cybersecurity throughout their lifecycle. That lifecycle framing is important. Security is not a one-time property of the model. It depends on how the model is deployed, what data it processes, how it is updated, how it is monitored, and how its surrounding infrastructure is protected.
Confidential computing can help secure parts of that lifecycle, especially where organizations want to run AI workloads on shared, remote, or hybrid infrastructure without exposing sensitive data or models to the underlying platform.
This is why confidential AI is becoming such an important use case. It is not only about privacy. It is also about protecting intellectual property, reducing third-party risk, supporting regulated inference, and enabling organizations to adopt AI without giving up control over sensitive assets.
The same idea is starting to appear in AI policy discussions beyond traditional compliance. For example, public comments related to the USAmerican AI Exports Program have recommended accelerator-level confidential computing as one way to protect AI model weights and systems in export packages. That is not the same as a regulatory mandate, but it shows how confidential computing is entering wider discussions about AI security, trust, and geopolitical risk.
Other frameworks point in the same direction
Not every relevant framework is built around privacy, financial resilience, or AI. Some are sector-specific or industry-led, but they point to the same underlying issue.
ThePayment Card Industry Data Security Standard is designed to protect payment account data through technical and operational requirements.PCI DSS v4.0.1 is not a confidential computing regulation, but payment environments often involve sensitive data moving through memory, applications, and processing systems. For high-risk payment workloads, runtime protection can become part of a broader defence-in-depth strategy.
TheCloud Security Alliance has also highlighted the need for cloud-native security architectures and guidance for protecting sensitive workloads in modern cloud environments. Its work is not regulation, but it often shapes how cloud providers and customers think about practical controls.
Singapore'sMonetary Authority of Singapore provides technology risk management guidance for financial institutions. Like DORA and PRA SS2/21, it reflects a wider financial-sector expectation: organizations need strong governance and technical controls for technology risk, especially where critical or sensitive workloads depend on third-party infrastructure.
The pattern is consistent. Whether the language is data in use, data in memory, secure processing, operational resilience, cybersecurity, or zero trust, the direction is the same: sensitive data needs protection during computation, not only before and after it.
A new baseline for sensitive workloads
The end result of all this is clear to see: regulation is becoming more concerned with how data is processed, instead of solely focusing on where and how it is stored. Financial risk management is becoming more focused on third-party technology dependencies. AI regulation is making lifecycle security more important. Healthcare and data-sharing initiatives are making secure processing environments more important. Sovereignty discussions are moving beyond location and into technical control.
All of these trends point toward the same conclusion: data in use is becoming a regulatory concern.
Confidential computing will not be mandatory for every workload. It will not replace existing security controls. It will not eliminate the need to trust hardware vendors, firmware, guest software or the application itself.
But for sensitive and regulated workloads, it gives organizations a way to shrink the trust boundary, strengthen runtime protection and provide stronger evidence that systems are being designed with confidentiality in mind.
That is why confidential computing is becoming part of the compliance conversation. Encryption at rest and in transit gave us the first two pillars of data protection. Confidential computing adds the third: protection while data is in use.
For organizations building the next generation of regulated cloud, edge, AI, and data-sharing systems, that third pillar is becoming much harder to treat as optional.
The role of Canonical and Ubuntu
Confidential computing is often described as a hardware capability. That is true, but it is only part of the story. Regulated organizations do not deploy processors in isolation. They deploy platforms. They need kernels, hypervisors, images, firmware, tooling, security updates, and long-term maintenance that work together.
That is why the operating system is important for confidential computing. With Ubuntu 26.04 LTS, Canonical brings integrated host and guest support for both AMD SEV-SNP and Intel TDX. These are two of the main technologies used to protect confidential virtual machines, and supporting both sides of the stack is what makes confidential computing practical for real deployments.
For regulated organizations, this is what turns confidential computing from a hardware feature into something they can confidently deploy at scale. If you're interested in discussing your confidential computing needs in more detail, don't hesitate to contact us .
Most organizations already understand encryption at rest and encryption in transit. These controls are mature, widely deployed, and often explicitly referenced in security frameworks. However, runtime is different: when an application processes sensitive information, that data is typically available in memory. In a traditional infrastructure model, the workload owner may need to trust a large [...]
Source: https://ubuntu.com//blog/confidential-computing-and-the-new-regulatory-focus-on-data-in-use Jul 24, 2026, 06:27 PM
#3
Ubuntu Blog / A day in the life of an Andro...
Last post by tim - Jul 29, 2026, 04:41 AMA day in the life of an Android developer with Anbox Cloud
Meet Alex, an Android developer. Like many developers, Alex would rather spend the day building applications than managing devices, maintaining emulators, or hunting for the right test environment. Thankfully, Alex is using Anbox Cloud, which simplifies their workflows and keeps them focused on development.
In this article, we'll follow Alex through their day to show you how it works, from feature development to release. Alex's focus for today is building a ride-tracking feature for their ride-sharing app. It'll need to be developed, tested, reviewed, and released.
9am: Building the feature
Alex starts their day by launching an instance in Anbox Cloud. Within seconds, they have a running Android environment. They connect the Android instance to their local development environment using Connect ADB. After authorizing the connection, they are ready to start building the feature using the development tools they are already familiar with.
The ride tracker relies on location data, so Alex needs to verify how the application behaves in different cities. They use the Set location feature, search for "London", and select the place they want to test. The moment they send the location update, their application immediately responds to the change, just as if they were right there! Alex clicks directly on the map to refine the exact pickup spot.
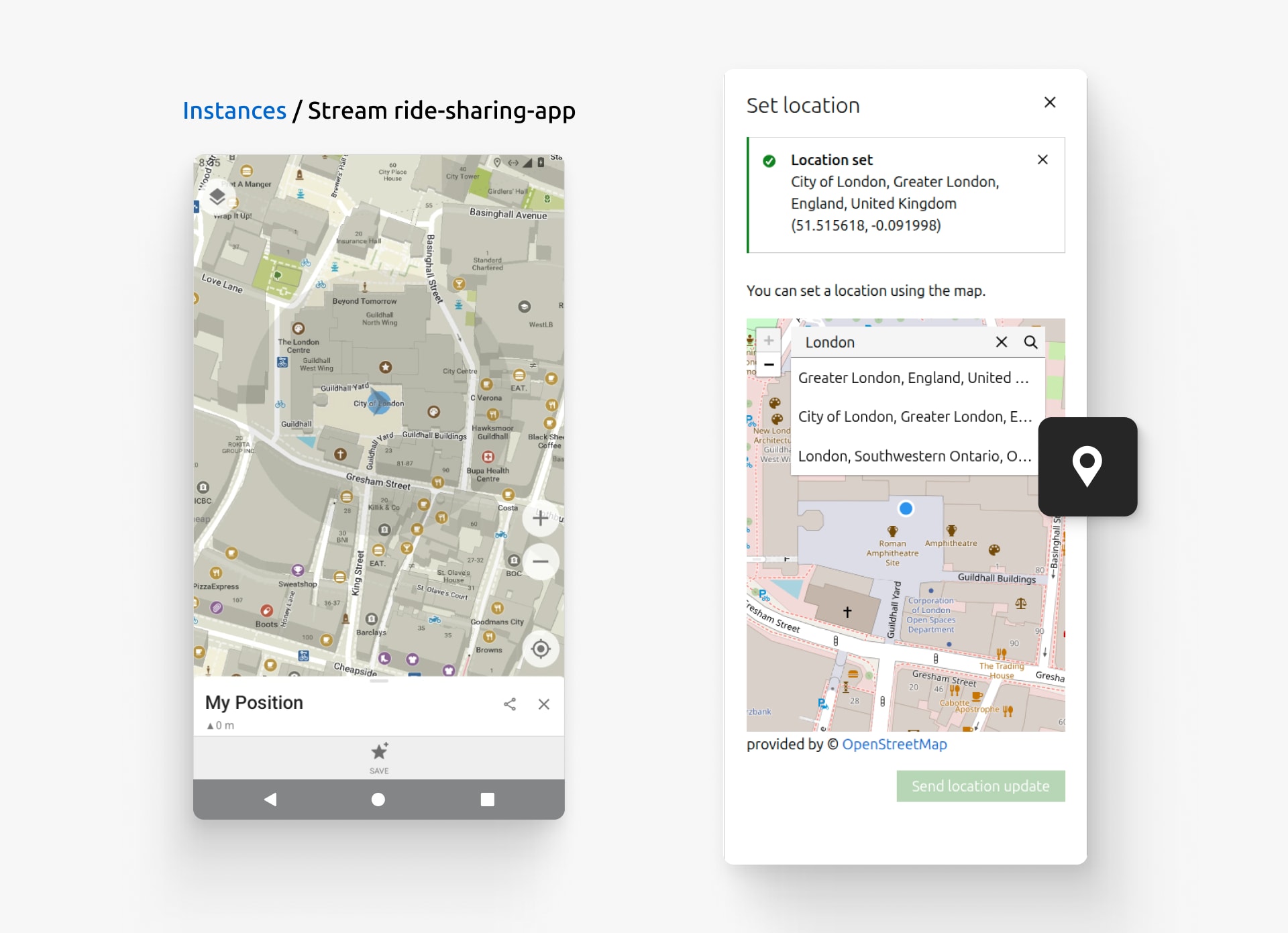 Search for a location or select a point directly on the map to update the device's GPS location.
Search for a location or select a point directly on the map to update the device's GPS location.
Alex also wants the ride-sharing experience to stay consistent across different devices. They rotate between portrait and landscape mode, confirming that the map, ride details, and action buttons remain easy to use regardless of how the device is held.
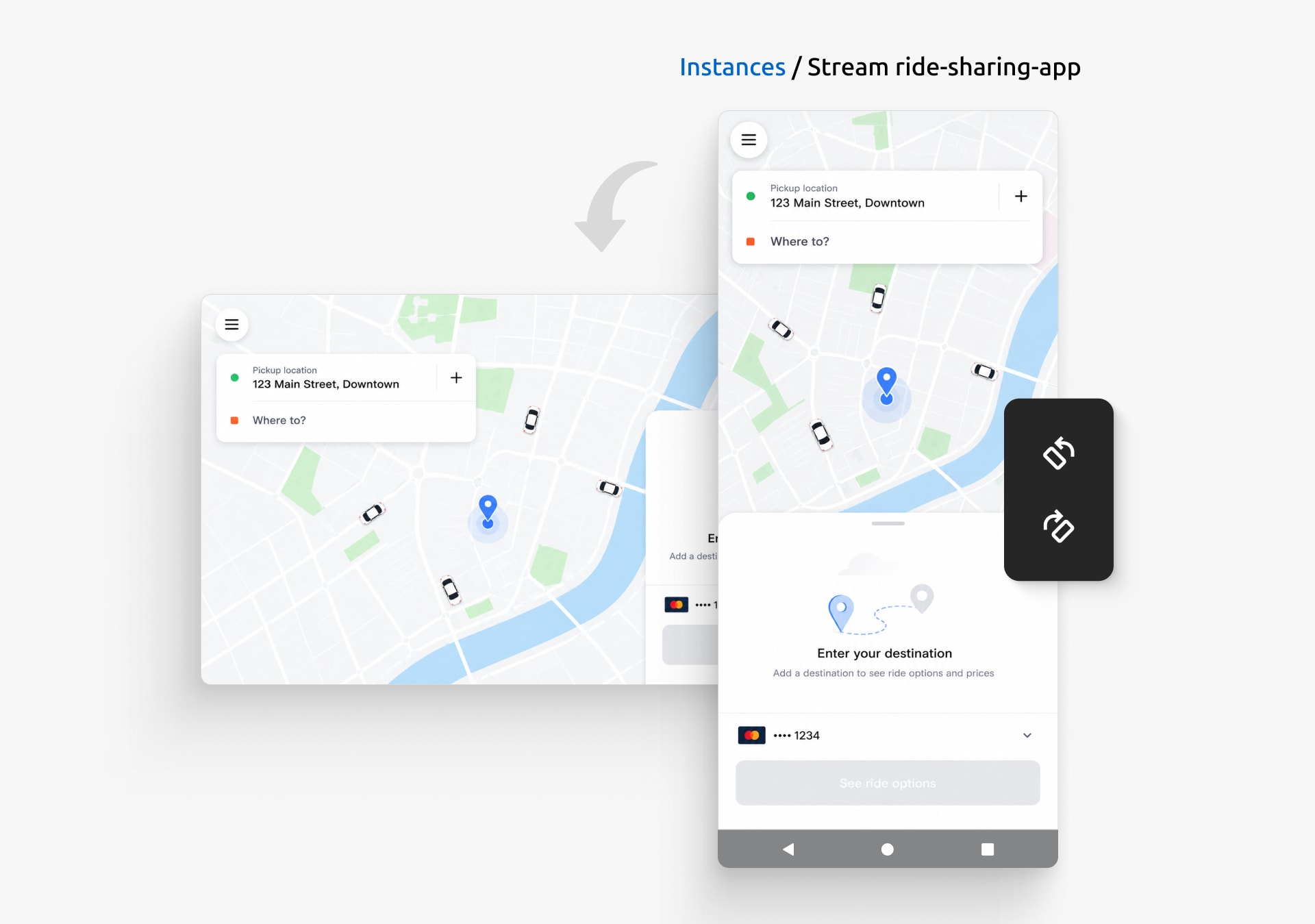 Quickly switch between portrait and landscape to verify the experience in both orientations.
Quickly switch between portrait and landscape to verify the experience in both orientations.
They then resize the Android device to test the ride-tracking feature across different screen sizes, switching to full screen when they want a closer look at the overall experience. Alex can use the interface to test a full range of devices their users carry.
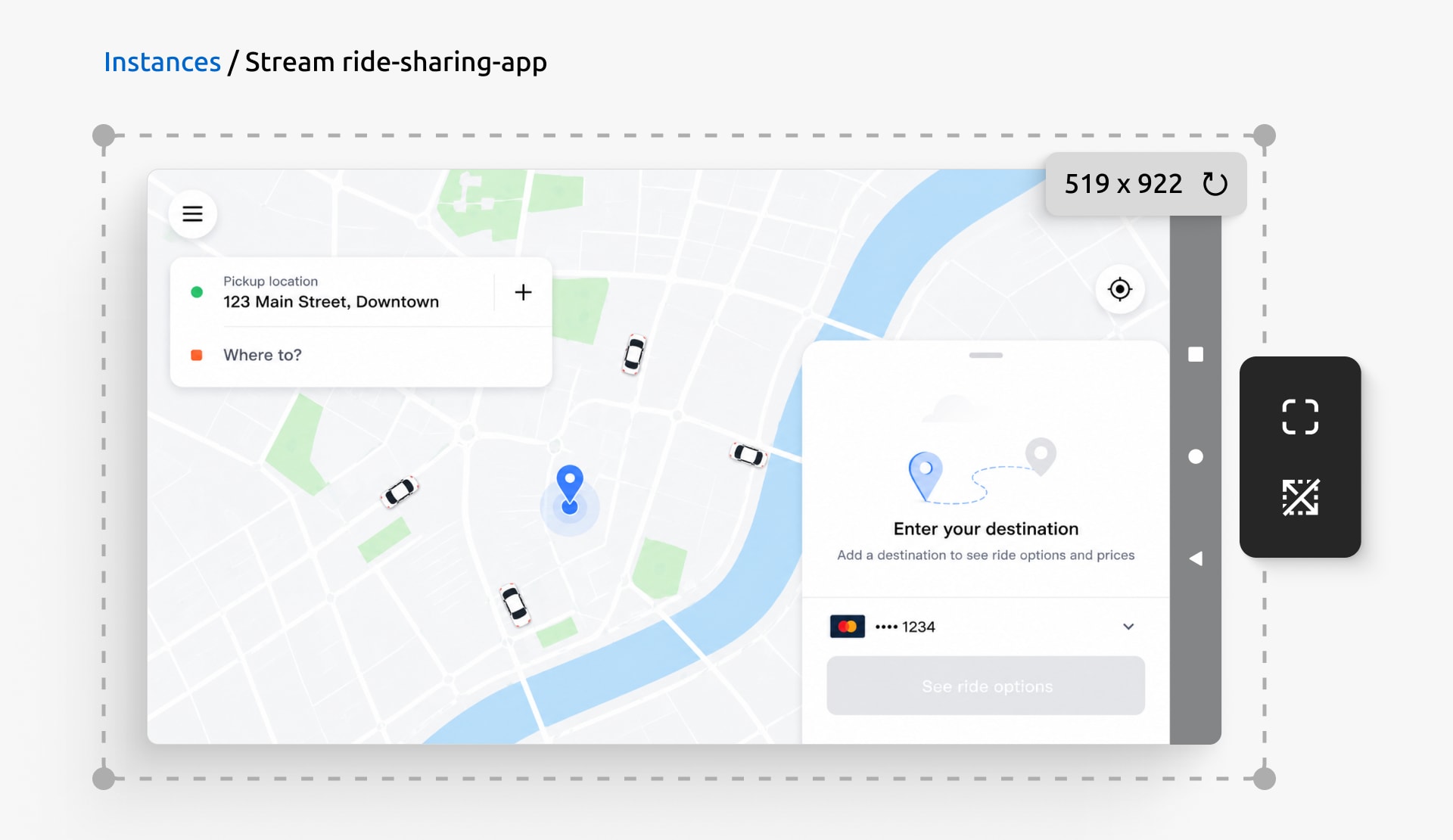 Resize the Android instance to validate the application across a range of screen sizes.
Resize the Android instance to validate the application across a range of screen sizes.
Exploring the different user journeys, Alex navigates the app using the device controls built right into the stream page. They tap Back to step backward through the booking flow, retracing the steps a rider takes when they change their mind about a destination. They press Home to jump straight back to the main screen where a rider requests a ride. And they use Power to put the device to sleep, then wake it again: the ride-sharing application resumes exactly where the user left off.
12pm: Feature review
Confident the feature is ready for review, Alex sets up a shareable link. They click the Set up sharing button, set a title and expiry for the shared stream. Within seconds, they have a link ready to send. The designer and the rest of the team open the running Android application right in their browsers to try the new ride-tracking feature for themselves.
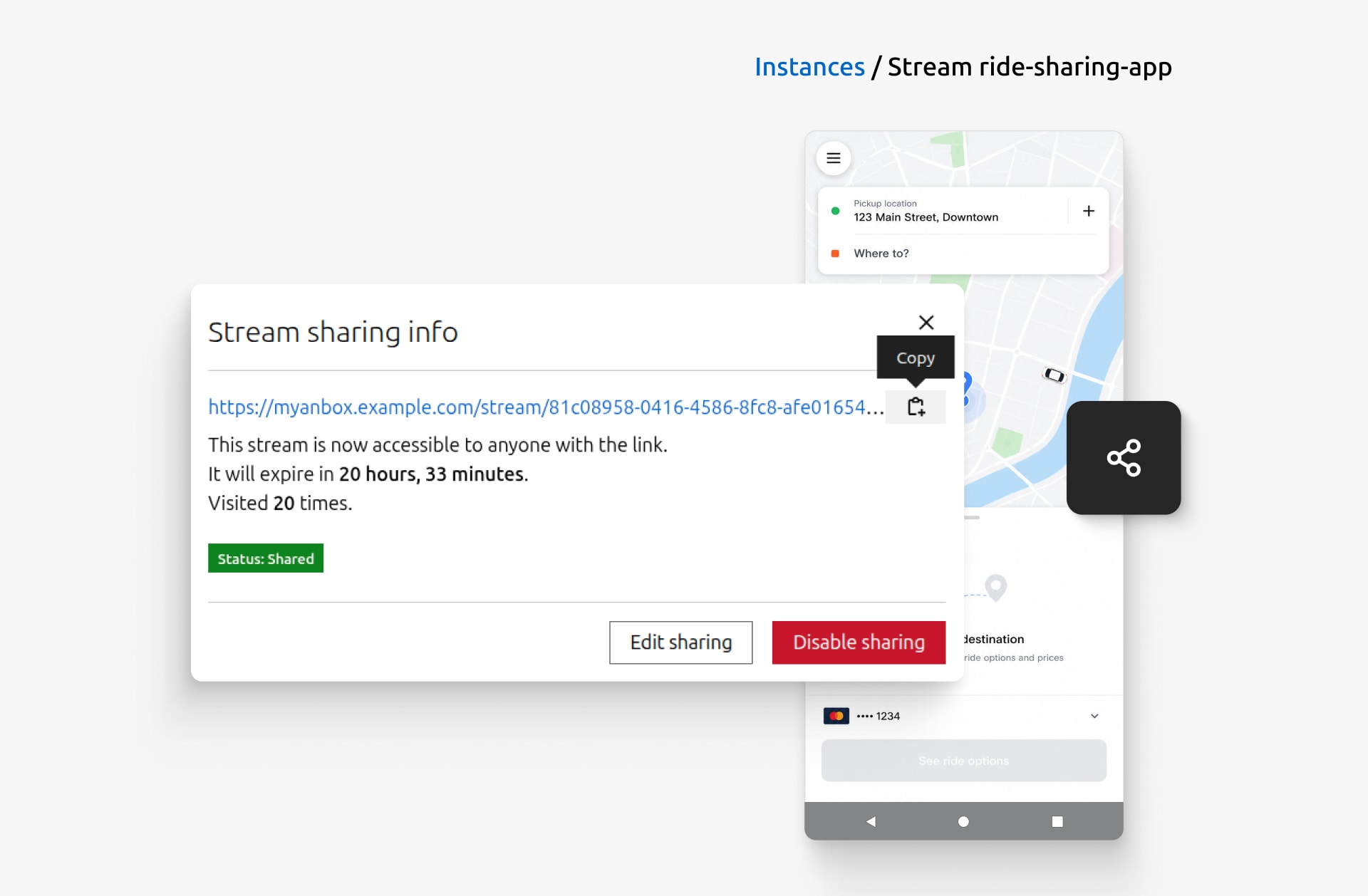 Create a shareable link so others can access the running application directly from their browsers.
Create a shareable link so others can access the running application directly from their browsers.
As feedback starts coming in, team members interact with the Android instance in the way that suits them. Keyboard-first users, for instance, can navigate the streaming interface and access its controls using built-in keyboard shortcuts, making common actions faster and more accessible. When they need to use browser-native shortcuts, such as Ctrl+R, they can temporarily disable the keyboard capture using a keyboard shortcut. This lets them seamlessly switch between interacting with the Android instance and using browser-native shortcuts, all without reaching for the mouse.
3pm: Fixing bugs and setting up automated testing
The hands-on testing pays off: the QA team reports a bug that only appears when switching between locations during a ride. Alex opens the Developer tools and inspects the application logs to understand what's happening behind the scenes. They filter log entries by severity, search for specific messages, and pause the live log stream while investigating the issue. Once Alex identifies the root cause, they export the relevant logs and share them with the team, resolving the issue and restoring the expected behavior.
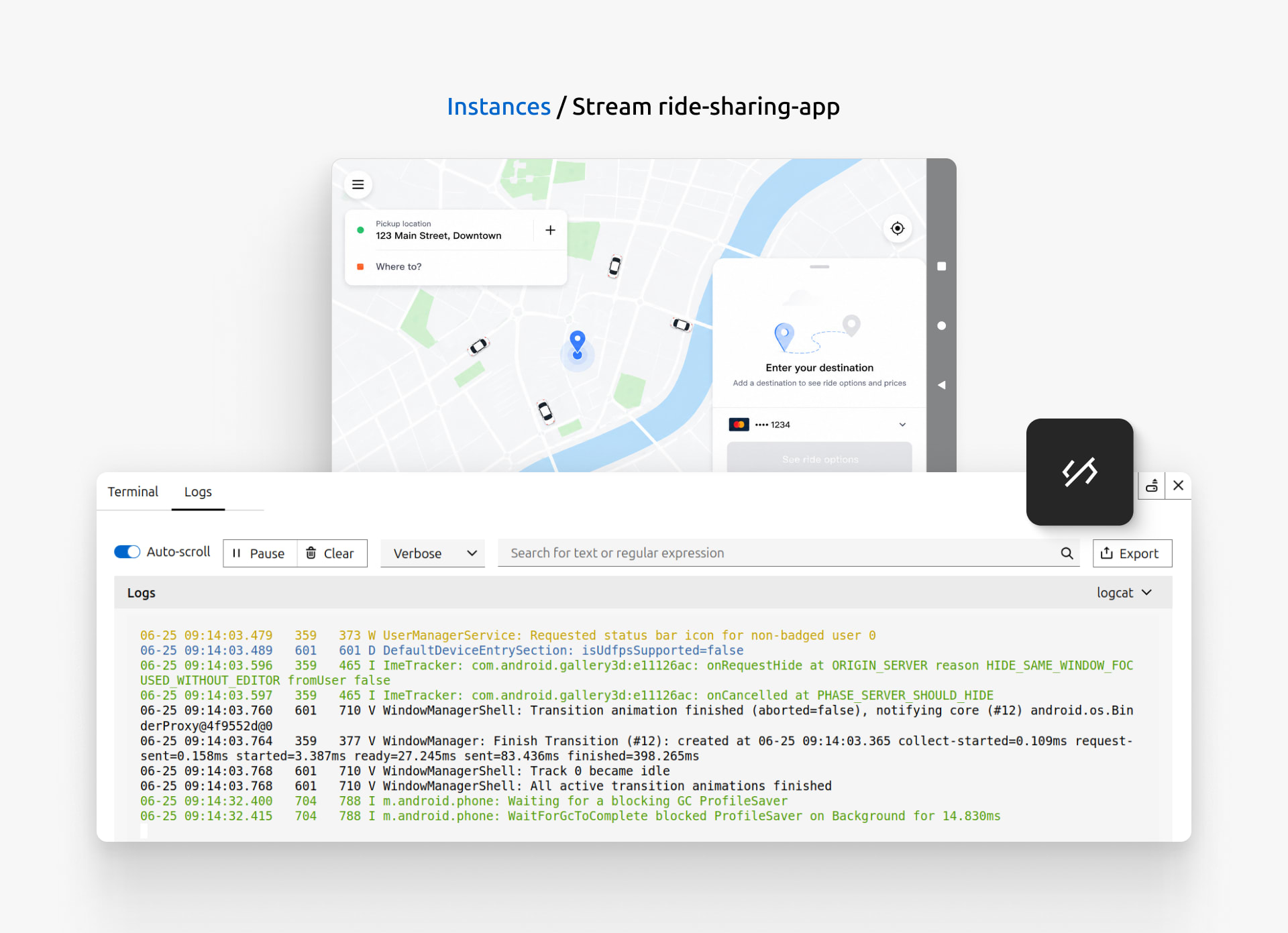 Use the Developer tools to investigate issues through live android and system level logs.
Use the Developer tools to investigate issues through live android and system level logs.
To avoid running into similar issues, Alex writes automated tests for the new ride-tracking feature and integrates them into their CI/CD pipeline. Using Anbox Cloud GitHub Actions, whenever the workflow runs, a fresh Android environment is provisioned automatically. This ensures that future changes won't introduce any regressions to the ride-sharing application.
5pm: Preparing to ship
Now that the feature is complete, Alex is finally ready to ship it to users. Before announcing the release, Alex uses the screenshots feature to highlight key parts of the ride-tracking experience and records a short demo using the screen recording feature. Alex then uses these assets to prepare the release notes, documentation, and announcement.
Alex knows that if anything about the stream ever needs looking into, the Download bug report button is one click away. It quickly collects diagnostic information that can be used to investigate the issue or shared with the Anbox Cloud team.
By the end of the day, Alex has taken the ride-tracking feature from first line of code to finished release: developing, testing, debugging, and automating, all from a single platform. And that's a day in the life of an Android developer with Anbox Cloud.
Explore Anbox Cloud in action and discover how it can streamline your development workflow!
Further reading
Meet Alex, an Android developer. In this article, we'll follow Alex through their day to show you how Anbox Cloud supports Alex from feature development to release. Alex's focus for today is building a ride-tracking feature for their ride-sharing app.
Categories: anbox cloud, Android Development
Source: https://ubuntu.com//blog/android-development-with-anbox-cloud Jul 24, 2026, 02:12 PM
Meet Alex, an Android developer. Like many developers, Alex would rather spend the day building applications than managing devices, maintaining emulators, or hunting for the right test environment. Thankfully, Alex is using Anbox Cloud, which simplifies their workflows and keeps them focused on development.
In this article, we'll follow Alex through their day to show you how it works, from feature development to release. Alex's focus for today is building a ride-tracking feature for their ride-sharing app. It'll need to be developed, tested, reviewed, and released.
9am: Building the feature
Alex starts their day by launching an instance in Anbox Cloud. Within seconds, they have a running Android environment. They connect the Android instance to their local development environment using Connect ADB. After authorizing the connection, they are ready to start building the feature using the development tools they are already familiar with.
The ride tracker relies on location data, so Alex needs to verify how the application behaves in different cities. They use the Set location feature, search for "London", and select the place they want to test. The moment they send the location update, their application immediately responds to the change, just as if they were right there! Alex clicks directly on the map to refine the exact pickup spot.
Search for a location or select a point directly on the map to update the device's GPS location.Alex also wants the ride-sharing experience to stay consistent across different devices. They rotate between portrait and landscape mode, confirming that the map, ride details, and action buttons remain easy to use regardless of how the device is held.
Quickly switch between portrait and landscape to verify the experience in both orientations. They then resize the Android device to test the ride-tracking feature across different screen sizes, switching to full screen when they want a closer look at the overall experience. Alex can use the interface to test a full range of devices their users carry.
Resize the Android instance to validate the application across a range of screen sizes.Exploring the different user journeys, Alex navigates the app using the device controls built right into the stream page. They tap Back to step backward through the booking flow, retracing the steps a rider takes when they change their mind about a destination. They press Home to jump straight back to the main screen where a rider requests a ride. And they use Power to put the device to sleep, then wake it again: the ride-sharing application resumes exactly where the user left off.
12pm: Feature review
Confident the feature is ready for review, Alex sets up a shareable link. They click the Set up sharing button, set a title and expiry for the shared stream. Within seconds, they have a link ready to send. The designer and the rest of the team open the running Android application right in their browsers to try the new ride-tracking feature for themselves.
Create a shareable link so others can access the running application directly from their browsers.As feedback starts coming in, team members interact with the Android instance in the way that suits them. Keyboard-first users, for instance, can navigate the streaming interface and access its controls using built-in keyboard shortcuts, making common actions faster and more accessible. When they need to use browser-native shortcuts, such as Ctrl+R, they can temporarily disable the keyboard capture using a keyboard shortcut. This lets them seamlessly switch between interacting with the Android instance and using browser-native shortcuts, all without reaching for the mouse.
3pm: Fixing bugs and setting up automated testing
The hands-on testing pays off: the QA team reports a bug that only appears when switching between locations during a ride. Alex opens the Developer tools and inspects the application logs to understand what's happening behind the scenes. They filter log entries by severity, search for specific messages, and pause the live log stream while investigating the issue. Once Alex identifies the root cause, they export the relevant logs and share them with the team, resolving the issue and restoring the expected behavior.
Use the Developer tools to investigate issues through live android and system level logs.To avoid running into similar issues, Alex writes automated tests for the new ride-tracking feature and integrates them into their CI/CD pipeline. Using Anbox Cloud GitHub Actions, whenever the workflow runs, a fresh Android environment is provisioned automatically. This ensures that future changes won't introduce any regressions to the ride-sharing application.
5pm: Preparing to ship
Now that the feature is complete, Alex is finally ready to ship it to users. Before announcing the release, Alex uses the screenshots feature to highlight key parts of the ride-tracking experience and records a short demo using the screen recording feature. Alex then uses these assets to prepare the release notes, documentation, and announcement.
Alex knows that if anything about the stream ever needs looking into, the Download bug report button is one click away. It quickly collects diagnostic information that can be used to investigate the issue or shared with the Anbox Cloud team.
By the end of the day, Alex has taken the ride-tracking feature from first line of code to finished release: developing, testing, debugging, and automating, all from a single platform. And that's a day in the life of an Android developer with Anbox Cloud.
Explore Anbox Cloud in action and discover how it can streamline your development workflow!
Further reading
- Virtualized Android comes to Anbox Cloud
- Cloud-native Android™ infotainment: your CI pipeline shouldn't depend on hardware
- Install on GitHub with Anbox Cloud GitHub Actions
- Access an Android Instance
Meet Alex, an Android developer. In this article, we'll follow Alex through their day to show you how Anbox Cloud supports Alex from feature development to release. Alex's focus for today is building a ride-tracking feature for their ride-sharing app.
Categories: anbox cloud, Android Development
Source: https://ubuntu.com//blog/android-development-with-anbox-cloud Jul 24, 2026, 02:12 PM
#4
Ubuntu News / Ubuntu 26.04 virtualization H...
Last post by tim - Jul 29, 2026, 04:41 AMUbuntu 26.04 virtualization HWE stack offers newer QEMU & libvirt
 Ubuntu's hardware enablement (HWE) effort has expanded to include backports of newer virtualisation tech to users of the current LTS release. The virtualization HWE stack from Canonical will let users benefit from newer versions of QEMU, libvirt and related firmware on top of their exiting LTS install, refreshed every 6 months for 2 years, without the need to seek out via third-party repos. Or, to quote Canonical's Ijlal Loutfi, it gives companies "the operational confidence of an LTS release, with a path to newer virtualization capabilities when they need them". If you're not familiar with the HWE, it's what brings newer [...]
Ubuntu's hardware enablement (HWE) effort has expanded to include backports of newer virtualisation tech to users of the current LTS release. The virtualization HWE stack from Canonical will let users benefit from newer versions of QEMU, libvirt and related firmware on top of their exiting LTS install, refreshed every 6 months for 2 years, without the need to seek out via third-party repos. Or, to quote Canonical's Ijlal Loutfi, it gives companies "the operational confidence of an LTS release, with a path to newer virtualization capabilities when they need them". If you're not familiar with the HWE, it's what brings newer [...]
You're reading Ubuntu 26.04 virtualization HWE stack offers newer QEMU & libvirt , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, Canonical, HWE, QEMU, Ubuntu 26.04 LTS
Source: https://www.omgubuntu.co.uk/2026/07/ubuntu-26-04-virtualization-hwe-stack Jul 28, 2026, 08:53 PM
Ubuntu's hardware enablement (HWE) effort has expanded to include backports of newer virtualisation tech to users of the current LTS release. The virtualization HWE stack from Canonical will let users benefit from newer versions of QEMU, libvirt and related firmware on top of their exiting LTS install, refreshed every 6 months for 2 years, without the need to seek out via third-party repos. Or, to quote Canonical's Ijlal Loutfi, it gives companies "the operational confidence of an LTS release, with a path to newer virtualization capabilities when they need them". If you're not familiar with the HWE, it's what brings newer [...]You're reading Ubuntu 26.04 virtualization HWE stack offers newer QEMU & libvirt , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, Canonical, HWE, QEMU, Ubuntu 26.04 LTS
Source: https://www.omgubuntu.co.uk/2026/07/ubuntu-26-04-virtualization-hwe-stack Jul 28, 2026, 08:53 PM
#5
Ubuntu News / We finally revived our Firefo...
Last post by tim - Jul 29, 2026, 04:41 AMWe finally revived our Firefox add-on (10 years late)
 The official OMG! Ubuntu add-on for Firefox is back – albeit far later than planned (sorry about that). If you've used our Chrome extension over the last decade, this add-on will be familiar as it's the same thing, just in Firefox. Same look and (almost) the same features because it's the same code (albeit with API name swaps and manifest tweaks). This isn't the first time this blog has offered a Firefox add-on. Our old one broke in 2017 and though we intended to fix it, a decade happened to fly straight past us. Like the Chrome version, it provides [...]
The official OMG! Ubuntu add-on for Firefox is back – albeit far later than planned (sorry about that). If you've used our Chrome extension over the last decade, this add-on will be familiar as it's the same thing, just in Firefox. Same look and (almost) the same features because it's the same code (albeit with API name swaps and manifest tweaks). This isn't the first time this blog has offered a Firefox add-on. Our old one broke in 2017 and though we intended to fix it, a decade happened to fly straight past us. Like the Chrome version, it provides [...]
You're reading We finally revived our Firefox add-on (10 years late) , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: Editorial, addons, Firefox, site stuff
Source: https://www.omgubuntu.co.uk/2026/07/omgubuntu-firefox-addon-notifier Jul 28, 2026, 01:28 PM
The official OMG! Ubuntu add-on for Firefox is back – albeit far later than planned (sorry about that). If you've used our Chrome extension over the last decade, this add-on will be familiar as it's the same thing, just in Firefox. Same look and (almost) the same features because it's the same code (albeit with API name swaps and manifest tweaks). This isn't the first time this blog has offered a Firefox add-on. Our old one broke in 2017 and though we intended to fix it, a decade happened to fly straight past us. Like the Chrome version, it provides [...]You're reading We finally revived our Firefox add-on (10 years late) , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: Editorial, addons, Firefox, site stuff
Source: https://www.omgubuntu.co.uk/2026/07/omgubuntu-firefox-addon-notifier Jul 28, 2026, 01:28 PM
#6
Ubuntu News / Mission Center adds battery, ...
Last post by tim - Jul 29, 2026, 04:41 AMMission Center adds battery, partition and power draw info
 A new version of Linux system monitoring app Mission Center is available for download, adding new hardware stats, first-run setup prompt and bug fixes. Mission Center 1.2.0 adds a new Battery page in the Performance tab, surfaces per-partition usage details on the Disk page with free and used space and adds a graph to the bottom of the CPU page that can optionally show temperature, power draw or CPU frequency. If you aren't on a laptop you may still see a Battery page as it can report battery information for peripherals too (albeit with the usual gotcha that power information [...]
A new version of Linux system monitoring app Mission Center is available for download, adding new hardware stats, first-run setup prompt and bug fixes. Mission Center 1.2.0 adds a new Battery page in the Performance tab, surfaces per-partition usage details on the Disk page with free and used space and adds a graph to the bottom of the CPU page that can optionally show temperature, power draw or CPU frequency. If you aren't on a laptop you may still see a Battery page as it can report battery information for peripherals too (albeit with the usual gotcha that power information [...]
You're reading Mission Center adds battery, partition and power draw info , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, App Updates, Mission center
Source: https://www.omgubuntu.co.uk/2026/07/mission-center-battery-power-draw-reporting Jul 28, 2026, 12:46 AM
A new version of Linux system monitoring app Mission Center is available for download, adding new hardware stats, first-run setup prompt and bug fixes. Mission Center 1.2.0 adds a new Battery page in the Performance tab, surfaces per-partition usage details on the Disk page with free and used space and adds a graph to the bottom of the CPU page that can optionally show temperature, power draw or CPU frequency. If you aren't on a laptop you may still see a Battery page as it can report battery information for peripherals too (albeit with the usual gotcha that power information [...]You're reading Mission Center adds battery, partition and power draw info , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, App Updates, Mission center
Source: https://www.omgubuntu.co.uk/2026/07/mission-center-battery-power-draw-reporting Jul 28, 2026, 12:46 AM
#7
Ubuntu News / Google Chrome arrives on Arm6...
Last post by tim - Jul 29, 2026, 04:41 AMGoogle Chrome arrives on Arm64 Linux, Widevine DRM included
 Google Chrome now has an official Arm64 Linux build, including for the Raspberry Pi, available via Google's Debian and RPM repos with Widevine DRM support.
Google Chrome now has an official Arm64 Linux build, including for the Raspberry Pi, available via Google's Debian and RPM repos with Widevine DRM support.
You're reading Google Chrome arrives on Arm64 Linux, Widevine DRM included , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, arm, ARM Laptops, Google Chrome, widevine
Source: https://www.omgubuntu.co.uk/2026/07/chrome-arm64-linux-available Jul 26, 2026, 11:42 PM
You're reading Google Chrome arrives on Arm64 Linux, Widevine DRM included , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, arm, ARM Laptops, Google Chrome, widevine
Source: https://www.omgubuntu.co.uk/2026/07/chrome-arm64-linux-available Jul 26, 2026, 11:42 PM
#8
Ubuntu News / Firefox’s new tab page adds A...
Last post by tim - Jul 29, 2026, 04:41 AMFirefox's new tab page adds AI-powered daily crossword widget
 More widgets are coming to Firefox's New Tab page, including an interactive crossword puzzle powered by the AI news reader Particle. The mini crossword game is updated daily, with puzzles based around recent content Particle's AI has ingested and summarised that day, and links to articles you can read to help deduce crossword answers. You click on a square to activate the row or column (clicking on it again switches between "Across" and "Down"). You read the clue at the bottom, and then you type in your answer. Use the hint button if you get stuck. If you just want [...]
More widgets are coming to Firefox's New Tab page, including an interactive crossword puzzle powered by the AI news reader Particle. The mini crossword game is updated daily, with puzzles based around recent content Particle's AI has ingested and summarised that day, and links to articles you can read to help deduce crossword answers. You click on a square to activate the row or column (clicking on it again switches between "Across" and "Down"). You read the clue at the bottom, and then you type in your answer. Use the hint button if you get stuck. If you just want [...]
You're reading Firefox's new tab page adds AI-powered daily crossword widget , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, AI/ML, Firefox, Mozilla
Source: https://www.omgubuntu.co.uk/2026/07/firefox-new-widgets-crossword Jul 24, 2026, 06:45 PM
More widgets are coming to Firefox's New Tab page, including an interactive crossword puzzle powered by the AI news reader Particle. The mini crossword game is updated daily, with puzzles based around recent content Particle's AI has ingested and summarised that day, and links to articles you can read to help deduce crossword answers. You click on a square to activate the row or column (clicking on it again switches between "Across" and "Down"). You read the clue at the bottom, and then you type in your answer. Use the hint button if you get stuck. If you just want [...]You're reading Firefox's new tab page adds AI-powered daily crossword widget , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, AI/ML, Firefox, Mozilla
Source: https://www.omgubuntu.co.uk/2026/07/firefox-new-widgets-crossword Jul 24, 2026, 06:45 PM
#9
Ubuntu News / Codeberg members vote to ban ...
Last post by tim - Jul 29, 2026, 04:41 AMCodeberg members vote to ban AI-generated code
 Codeberg, the nonprofit alternative to GitHub used to host FLOSS projects, will no longer host software that's "mostly" AI-generated. A vote closed yesterday (22 July, 2026), passing 358 to 144 with 14 abstentions on roughly 50% turnout to stop hosting software that's largely vibe-coded. A second motion, also passed, commits Codeberg to never training AI models on hosted code or user data. Not that it was ever likely to. A Terms of Use amendment now prohibits projects that "mostly consist of code written by" generative AI tools. In a blog post, Codeberg explains the economic need for a ban, explaining [...]
Codeberg, the nonprofit alternative to GitHub used to host FLOSS projects, will no longer host software that's "mostly" AI-generated. A vote closed yesterday (22 July, 2026), passing 358 to 144 with 14 abstentions on roughly 50% turnout to stop hosting software that's largely vibe-coded. A second motion, also passed, commits Codeberg to never training AI models on hosted code or user data. Not that it was ever likely to. A Terms of Use amendment now prohibits projects that "mostly consist of code written by" generative AI tools. In a blog post, Codeberg explains the economic need for a ban, explaining [...]
You're reading Codeberg members vote to ban AI-generated code , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, AI/ML, codeberg
Source: https://www.omgubuntu.co.uk/2026/07/codeberg-bans-ai-generated-code Jul 24, 2026, 12:51 AM
Codeberg, the nonprofit alternative to GitHub used to host FLOSS projects, will no longer host software that's "mostly" AI-generated. A vote closed yesterday (22 July, 2026), passing 358 to 144 with 14 abstentions on roughly 50% turnout to stop hosting software that's largely vibe-coded. A second motion, also passed, commits Codeberg to never training AI models on hosted code or user data. Not that it was ever likely to. A Terms of Use amendment now prohibits projects that "mostly consist of code written by" generative AI tools. In a blog post, Codeberg explains the economic need for a ban, explaining [...]You're reading Codeberg members vote to ban AI-generated code , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, AI/ML, codeberg
Source: https://www.omgubuntu.co.uk/2026/07/codeberg-bans-ai-generated-code Jul 24, 2026, 12:51 AM
#10
Ubuntu News / Why Ubuntu 26.04 is hiding up...
Last post by tim - Jul 29, 2026, 04:41 AMWhy Ubuntu 26.04 is hiding update notifications [Fixed]
 If Ubuntu 26.04 LTS hasn't nagged you about pending updates in a while, there's a reason for that. A Launchpad bug report and related discussion on the Ubuntu Discourse noticed that the distro's update-manager no longer notifies when updates are pending unless the update notification tray icon is enabled. The rub? That tray icon as turned off in Ubuntu 26.04 (with no toggle in Settings to turn it back on). It's not as "risky" as it sounds, though. Ubuntu ships with unattended-upgrades enabled by default, which installs security updates in the background – you're just not told about them. Turn [...]
If Ubuntu 26.04 LTS hasn't nagged you about pending updates in a while, there's a reason for that. A Launchpad bug report and related discussion on the Ubuntu Discourse noticed that the distro's update-manager no longer notifies when updates are pending unless the update notification tray icon is enabled. The rub? That tray icon as turned off in Ubuntu 26.04 (with no toggle in Settings to turn it back on). It's not as "risky" as it sounds, though. Ubuntu ships with unattended-upgrades enabled by default, which installs security updates in the background – you're just not told about them. Turn [...]
You're reading Why Ubuntu 26.04 is hiding update notifications [Fixed] , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, bugs, Software Updater, Ubuntu 26.04 LTS
Source: https://www.omgubuntu.co.uk/2026/07/ubuntu-26-04-update-notifications-disabled Jul 22, 2026, 11:00 PM
You're reading Why Ubuntu 26.04 is hiding update notifications [Fixed] , a blog post from OMG! Ubuntu . Do not reproduce elsewhere without permission.
Categories: News, bugs, Software Updater, Ubuntu 26.04 LTS
Source: https://www.omgubuntu.co.uk/2026/07/ubuntu-26-04-update-notifications-disabled Jul 22, 2026, 11:00 PM